
I am a master’s student in Software Engineering at Beihang University, advised by Prof. Qian Yu. My research is centered on visual code generation: building models that generate structured, editable visual code rather than rasterized outputs. I work at the intersection of multimodal large language models, vector graphics, and generative modeling, with two primary research threads. The first is SVG code generation, where I study how models can understand, reason over, and synthesize vector graphics programs, with representative works including Render-in-the-Loop and LLM4SVG. The second is vector animation code generation, where I build models that generate temporally coherent, structure-preserving vector animations directly in code, represented by VAnim and GroupSketch.
More broadly, I am interested in turning code-centric multimodal models into practical systems for creation and interaction. Currently, I am a Qingyun Program Research Intern in the Pre-training Group at Tencent YouTu Lab, working on native multimodal foundation large language models for vector graphics generation. My industry research focuses on applying MLLMs to visual code generation agents, and on building TTSScore, a trustworthy Text-to-SVG metric and benchmark for measuring the faithfulness between SVG outputs and text prompts. Previously, I worked on generative ranking and retrieval at Tencent Yuanbao, and on code agents and search agents within the iQuest foundation large language model team at Ubiquant Investment. These experiences further strengthen my goal of pushing AI beyond visual understanding toward controllable, executable, and production-ready visual code generation systems.
🔥 News
- 2026.06: 🎉🎉 Our paper Render-in-the-Loop has been accepted by ECCV 2026!
- 2026.05: 🎉🎉 Our paper VAnim has been accepted by ICML 2026!
- 2025.07: 🎉🎉 Our paper GroupSketch has been accepted by ACM MM 2025!
- 2025.02: 🎉🎉 Our paper LLM4SVG has been accepted by CVPR 2025!
📝 Publications
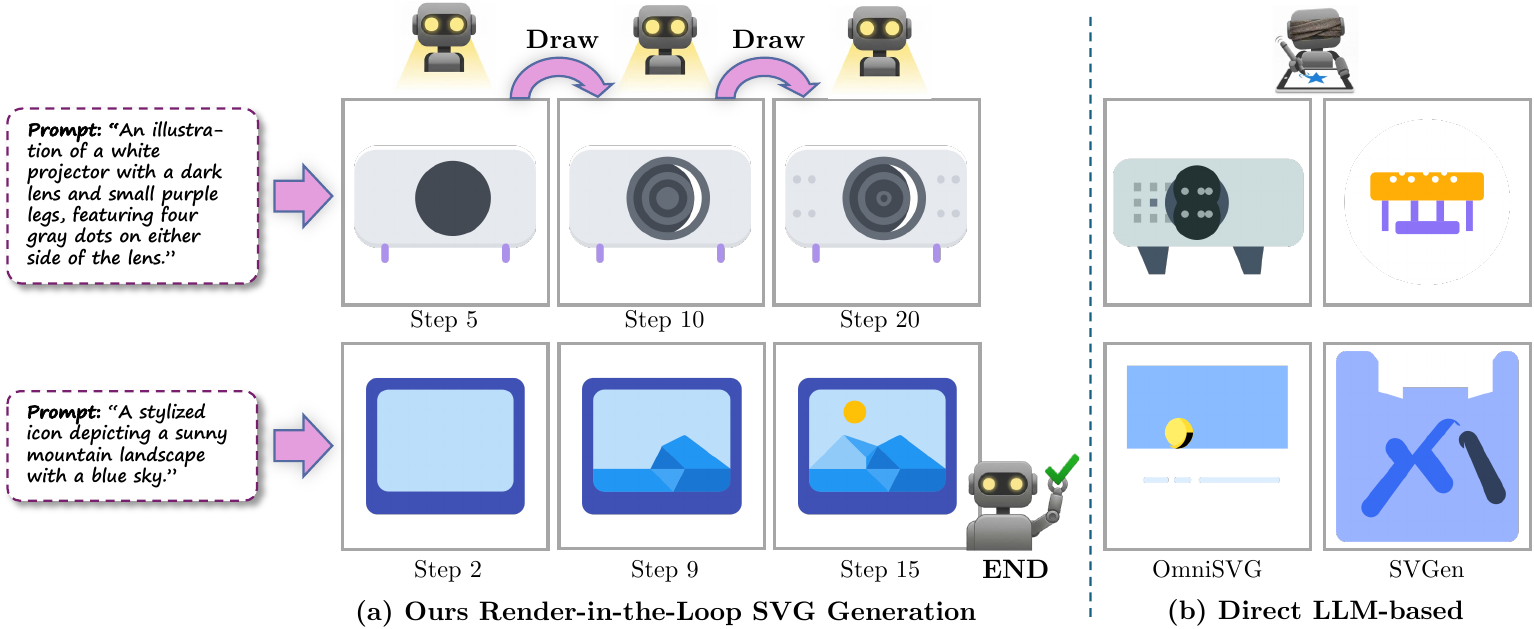
Render-in-the-Loop: Vector Graphics Generation via Visual Self-Feedback
Guotao Liang, Zhangcheng Wang, Juncheng Hu, Haitao Zhou, Ziteng Xue, Jing Zhang, Dong Xu, Qian Yu†
† Corresponding author.
![]()
![]()
![]()
TL;DR: Render-in-the-Loop closes the loop for SVG generation by rendering intermediate code states back into the MLLM, enabling Visual Self-Feedback training and Render-and-Verify inference for cleaner, more reliable vector graphics.
European Conference on Computer Vision (ECCV), 2026.
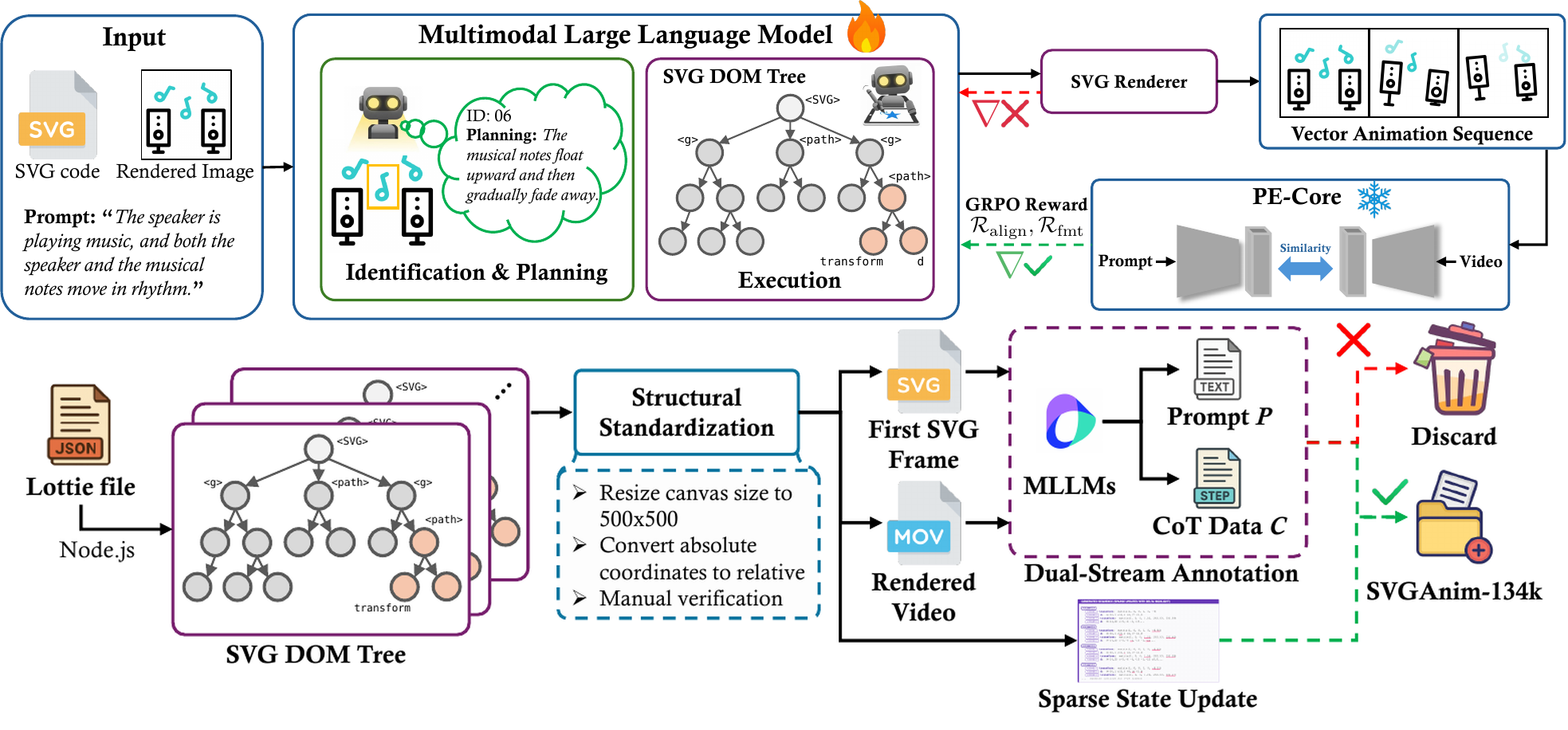
VAnim: Rendering-Aware Sparse State Modeling for Structure-Preserving Vector Animation
Guotao Liang, Zhangcheng Wang, Chuang Wang, Juncheng Hu, Haitao Zhou, Junhua Liu, Jing Zhang, Dong Xu, Qian Yu
![]()
![]()
TL;DR: VAnim formulates SVG animation as sparse state updates on a persistent DOM tree, combining identification-first motion planning with rendering-aware RL to generate structure-preserving vector animations from text.
International Conference on Machine Learning (ICML), 2026.
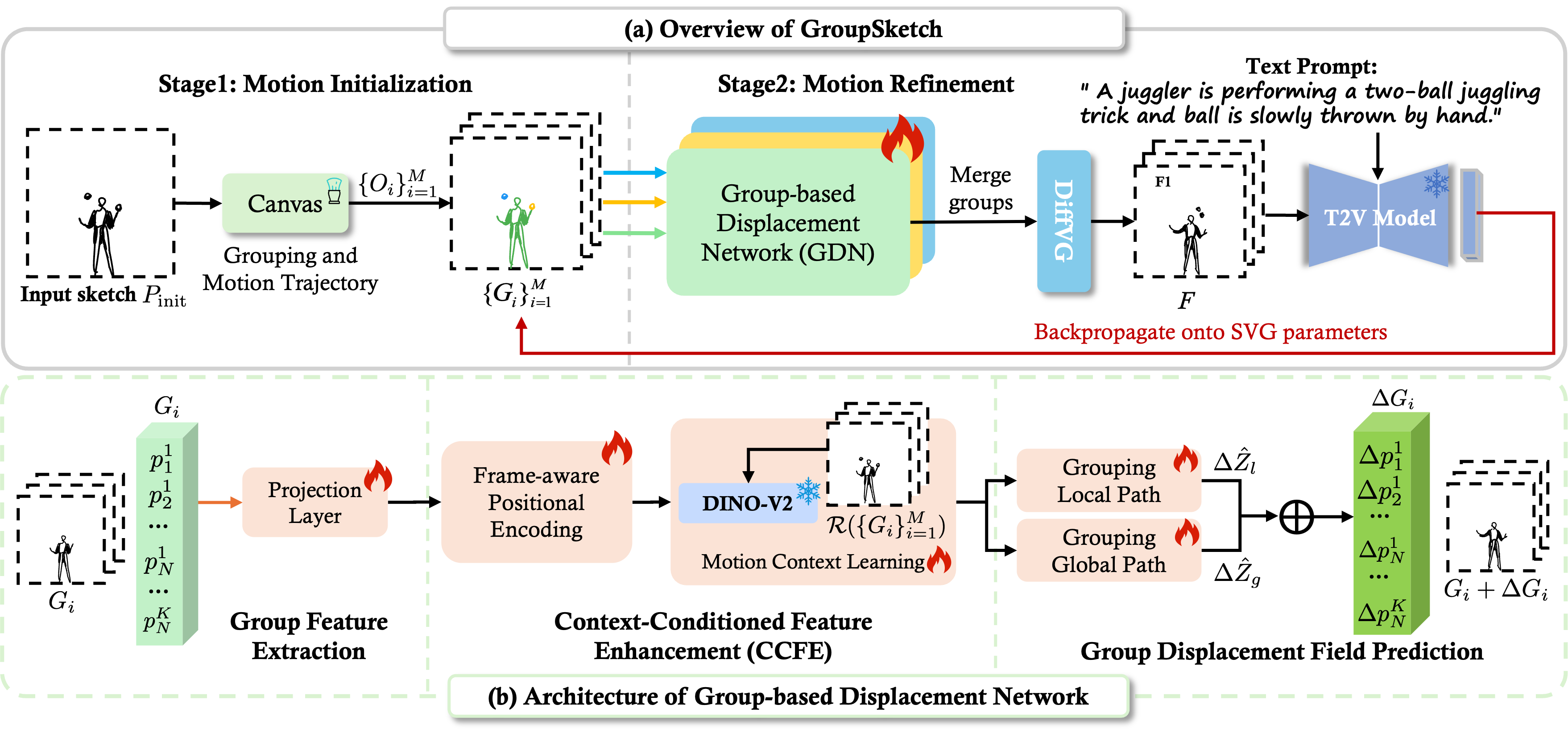
Multi-Object Sketch Animation with Grouping and Motion Trajectory Priors
Guotao Liang, Juncheng Hu, Ximing Xing, Jing Zhang, Qian Yu
![]()

TL;DR: GroupSketch synthesizes multi-object sketch animations with grouping and motion trajectory priors, enabling users to create complex animations with ease.
ACM International Conference on Multimedia, 2025.
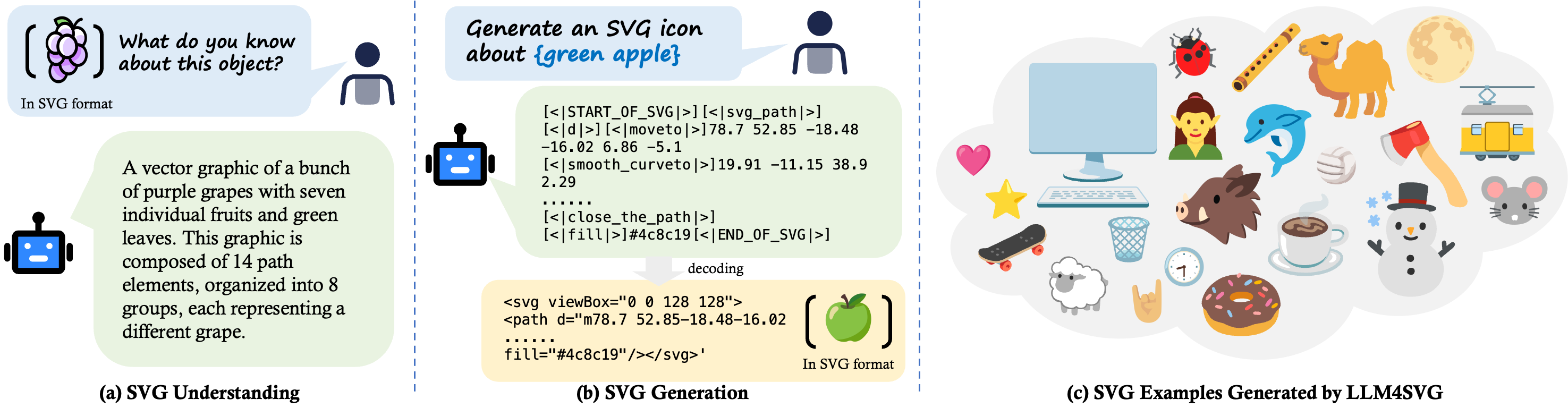
Empowering LLMs to Understand and Generate Complex Vector Graphics
Ximing Xing, Juncheng Hu, Guotao Liang, Jing Zhang, Dong Xu, Qian Yu
![]()

TL;DR: LLM4SVG introduces learnable SVG Semantic Tokens and a large SVGX-SFT dataset, enabling LLMs to understand and generate complex vector graphics.
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
🌐 Project | 📁 Code | 🤗 SVGX-SFT-1M Dataset
📖 Educations
- 2024.09 – Present: M.S. in Software Engineering, School of Software, Beihang University
💻 Internships
-
2026.06 – Present, Tencent YouTu Lab, Research Intern, Qingyun Program, Pre-training Group — Beijing, China
Working on native multimodal foundation large language models for vector graphics generation, with a focus on visual code generation agents and TTSScore, a trustworthy Text-to-SVG metric and benchmark for evaluating faithfulness between SVG outputs and text prompts. -
2026.03 – 2026.06, Ubiquant Investment, Algorithm Intern, iQuest Foundation Large Language Model Team — Beijing, China
Worked on code agent and search agent training/post-training within the iQuest foundation large language model team. -
2025.10 – 2026.02, Tencent Yuanbao, Algorithm Intern, Yuanbao Search Department — Beijing, China
Working on generative ranking and retrieval with multimodal large language models. -
2025.05 – 2025.09, 4Paradigm, Research Intern — Beijing, China
Conducted research on multimodal large language models for vector graphics animation.